관계형 데이터베이스 모델링 개요
모델
모델은 목적에 부합하는 모방이라 할 수 있다.
사람이 살아가면서 나타날 수 있는 다양한 현상은 사람 사물 개념 등에 의해 발생된다고 할 수 있으며 모델링은 이것을 표기법에 의해 규칙을 가지고 표기하는 것 자체를 의미한다. 즉 모델을 만들어가는 일 자체를 모델링으로 정의할 수 있다.
전체 흐름
업무파악 -> 개념적 데이터 모델링 -> 논리적 데이터 모델링 -> 물리적 데이터 모델링
- 개념적 데이터 모델링
- 각각의 개념들이 어떻게 상호작용 하는지 확인하는 과정
- 논리적 데이터 모델링
- 개념적 데이터 모델링을 우리가 아는 패러다임으로 변경하는 과정
- 물리적 데이터 모델링은
- 데이터베이스를 선택 후 실제 테이블을 생성하는 과정
업무 파악
필요한 것이 무엇인지 파악하기 위해 진행해야하는 단계로써
강의에서는 Ovenapp을 사용하여 시각화 하는 것을 예시로 알려주었다.
https://ovenapp.io/
개념적 데이터 모델링
ERD(Entity Relationshop Diagram)를 통해 나타낼 수 있음.
현실을 간단하게 나타낼 수 있는 방법이 무엇이 있을까?
ERD는 우리에게 현실을 3개의 관점에서 볼 수 있게 도와준다.
정보, 정보 그룹, 정보 그룹 사이의 관계. 이를 통해 우리는 추상화된 개념을 볼 수 있을 것이다.
ERD는 또한 쉽게 table로 나타낼 수 있다.
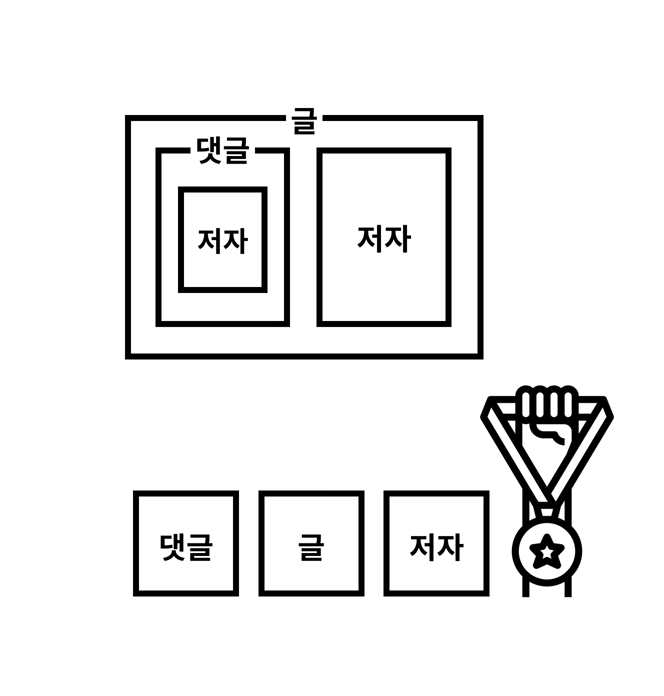
위와 아래 중 어떤 것이 관계형 데이터베이스를 표현하기에 적합할까? 정답은 아래이다. 관계형 데이터베이스에서는 내포관계를 표현할 수 없기 때문에 내포관계가 있는 표를 생성할 경우 매우 큰 데이터를 가진 표에 지나지 않을 것이다. 이는 데이터의 중복과 광대한 데이터를 불러오는 데 물리적으로 문제가 있을 수 있다.
아래와 같이 글, 저자, 댓글은 각각 ERD에서 Entity라 한다. 이는 이후에 table이 된다.
글의 본문, 제목, 생성일 등은 attribute이다. 이는 column이 된다.
그리고 글에 댓글을 쓰다라는 관계는 Relation이라 하며 Primary key, Foreign key
Identifier
가지고있는 데이터를 식별하기 위해 고유한 식별자를 사용해야 한다.
데이터가 가지고 있는 column값에서 식별자 후보군이 될 수 있는 키를 candidate key라 하며 여기서 선택된 식별자를 Primary key 그 외는 alternate key라 한다.
또한, 두 가지 이상의 값을 이용하여 식별할 수 있는 키들은 composite key라 한다.
Cardinality
1:1 담임 선생님은 반이 하나다. 반은 담임선생님이 하나다. 1:N 저자는 댓글을 여러개 작성할 수 있다. 댓글에게 저자는 하나다. N:M 저자는 글을 여러개 작성할 수 있다. 글은 여러명의 저자를 가질 수 있다. N:M 관계는 실제 관계형 구조에서는 쉽게 만들 수 없는 구조이기 때문에 연결테이블을 거쳐 만든다.
Optionality
저자는 반드시 댓글을 작성하지(가지지) 않아도 된다. 댓글은 반드시 저자를 가져야 한다. Mandatory:Optional
논리적 데이터 모델링
개념적 데이터 모델링을 관계형 데이터베이스 패러다임에 어울리는 형태로 변형하는 과정.
Mapping rule
ERD를 관계형 데이터베이스에 맞게 변형하기 위한 방법론이다. 설명보다는 간단하게 아래의 표로 생각하는 것이 이해하기 쉬울 것이다.
| ERD | RDB |
|---|---|
| Entity | Table |
| Attribute | Column |
| Relation | PK, FK |
관계형 데이터 모델 만들기
아래 ERD와 aquerytool 툴을 사용하여 만들었다.
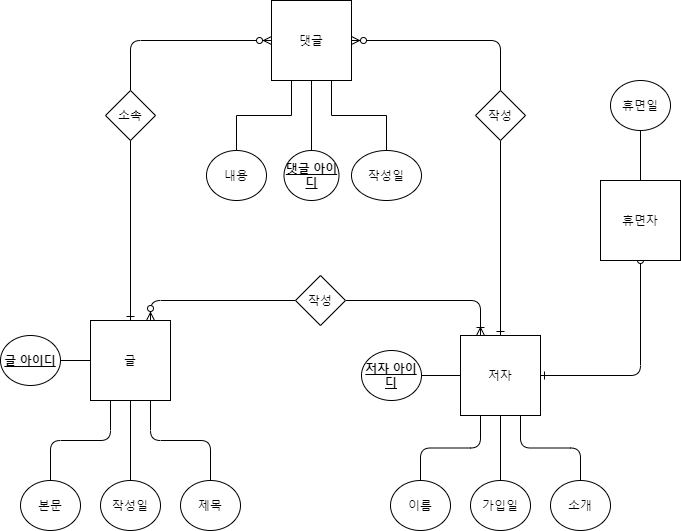
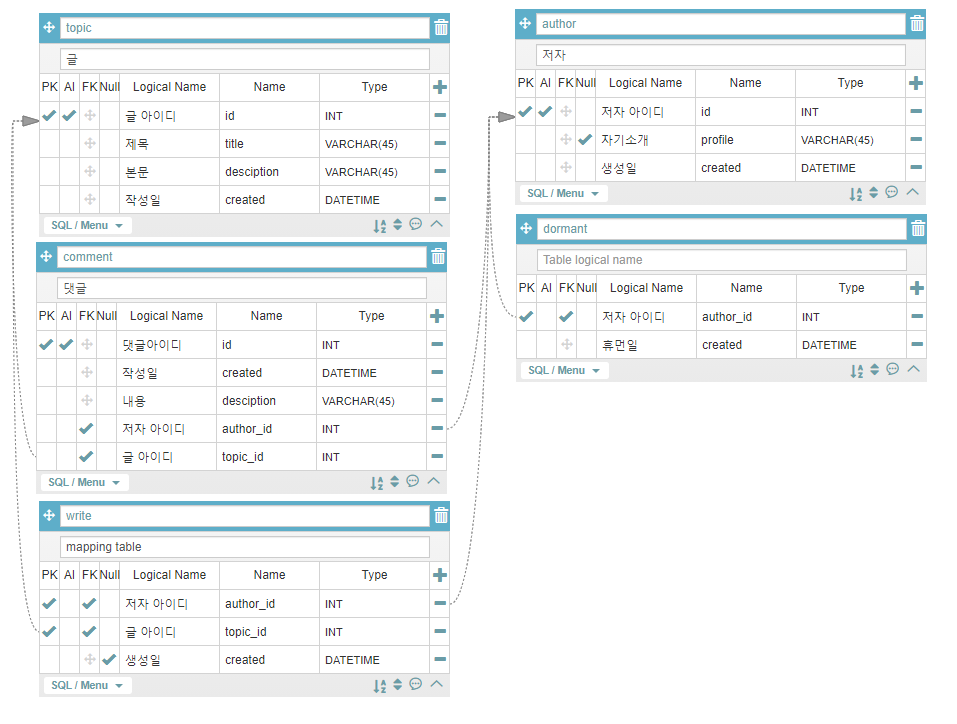
Mapping Table
N:M관계에서는 특정 테이블이 외래키를 가지는 방식으로 할 경우 필드에 다수의 값이 들어가게 될 것이다. 예를 들어 작성자는 글을 여러개 쓸 수 있으므로 필드에 복수의 키를 가져야 한다. 하지만 이는 관계형 데이터베이스에서 지양하므로 다른 방식을 선택해야 할 것이다.
Mapping Table
작성은 간단하다 단순히 작성자와 글의 키를 가지고 있는 테이블을 생성 후
그 둘 사이를 매핑하는 역할을 하는 것이다.
Normalization
관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화하는 프로세스를 정규화라고 한다.
정규화 된 단계를 정규형으로 표현하는데 보통은 3NF까지를 만족할 경우 정규화를 거쳤다 표현한다.
그 이후 단계는 학술적으로 사용되는 단계이기 때문에 우리는 3NF단계 까지 정규화를 해보도록 하겠다.
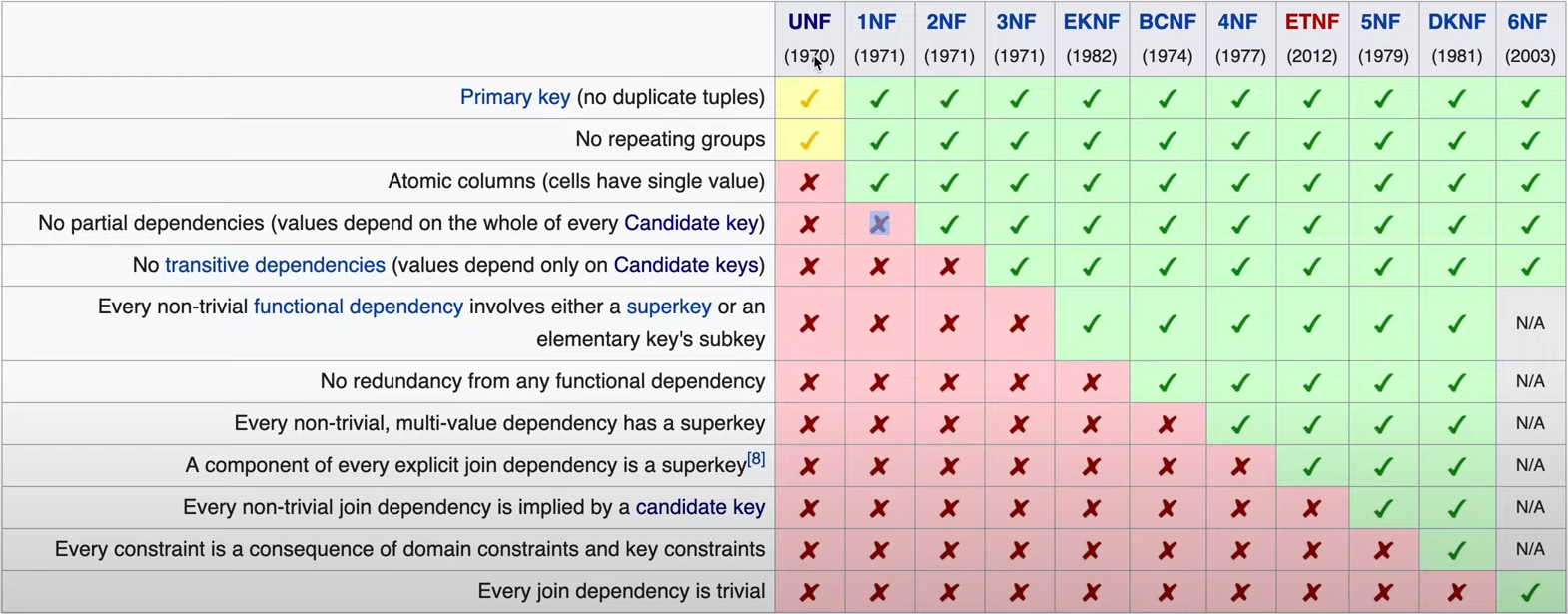
1NF
각 콜럼들이 서로
Atomic해야한다.
쉽게 말해 각각의 필드에 값이 하나만을 가져야 한다는 의미이다. 아래 표는 정규화 되지 않은 폼이다. 이를 변형하여 정규화 과정을 거쳐보자.
Unormalized form
| title | type | description | created | author_id | author_name | author_profile | price | tag |
|---|---|---|---|---|---|---|---|---|
| MySQL | paper | MySQL is … | 2011 | 1 | kim | developer | 10000 | rdb, free |
| MySQL | online | MySQL is … | 2011 | 1 | kim | developer | 0 | rdb, free |
| ORACLE | paper | ORACLE is … | 2012 | 1 | kim | developer | 15000 | rdb, commercial |
아래 표는 정규형을 만족시키지만 정보의 중복을 피하지 못한다. 그렇다면 어떻게 해야할까? 정보의 중복을 피하기위해서 가장 쉽게 생각할 수 있는 방식은 테이블을 나누는 것이다.
| title | type | description | created | author_id | author_name | author_profile | price | tag |
|---|---|---|---|---|---|---|---|---|
| MySQL | paper | MySQL is … | 2011 | 1 | kim | developer | 10000 | rdb |
| MySQL | paper | MySQL is … | 2011 | 1 | kim | developer | 10000 | free |
여기서 중요한건 현재 테이블과 tag가 N:M 관계라는 것이다. 앞에서 말했단 Mapping table을 이용하여 테이블을 나누어야 한다.
| title | type | description | created | author_id | author_name | author_profile | price |
|---|---|---|---|---|---|---|---|
| MySQL | paper | MySQL is … | 2011 | 1 | kim | developer | 10000 |
| MySQL | online | MySQL is … | 2011 | 1 | kim | developer | 0 |
| ORACLE | paper | ORACLE is … | 2012 | 1 | kim | developer | 15000 |
| id | name |
|---|---|
| 1 | rdb |
| 2 | free |
| 3 | commercial |
| topic_title | tag_id |
|---|---|
| MySQL | 1 |
| MySQL | 2 |
| ORACLE | 3 |
| ORACLE | 1 |
2NF
모든 비기본 속성(non-prime attribute; 후보 키에 속하지 않은 속성)들이 후보 키에 속한 속성들 전체에 함수 종속인 경우에 한해서 1NF 테이블은 2NF이다.
말만 들어선 뭔 소린지 감이 하나도 안잡힌다. 예시와 함께 봐보자
1NF
| title | type | description | created | author_id | author_name | author_profile | price |
|---|---|---|---|---|---|---|---|
| MySQL | paper | MySQL is … | 2011 | 1 | kim | developer | 10000 |
| MySQL | online | MySQL is … | 2011 | 1 | kim | developer | 0 |
| ORACLE | paper | ORACLE is … | 2012 | 1 | kim | developer | 15000 |
표를 보면 type 콜럼 대해서 중복이 발생하고 있다.
중복이 발생하는 이유는 무엇일까? 바로 partial dependencies 때문이다.
description부터 author_profile 콜럼까지의 속성은 title에 부분 족송되고 있다.
다른 말로 위 테이블은 title, type, price 콜럼을 위해 존재한다는 말이다.
테이블을 나누어 중복되는 값을 없애보자.
| title | description | created | author_id | author_name | author_profile |
|---|---|---|---|---|---|
| MySQL | MySQL is … | 2011 | 1 | kim | developer |
| ORACLE | ORACLE is … | 2012 | 1 | kim | developer |
| title | type | price |
|---|---|---|
| MySQL | paper | 10000 |
| MySQL | online | 0 |
| ORACLE | online | 0 |
3NF
테이블이 제2 정규형을 만족하고, 테이블 내의 모든 속성이 기본 키에만 의존하며, 다른 후보 키에 의존하지 않는다.
뭔지 알 것 같기도 한데 여전히 모른다면 다시 표와 함께 봐보자.
| title | description | created | author_id | author_name | author_profile |
|---|---|---|---|---|---|
| MySQL | MySQL is … | 2011 | 1 | kim | developer |
| ORACLE | ORACLE is … | 2012 | 1 | kim | developer |
author_id 값은 title에 종속되고 있다.
하지만 author_name, author_profile는 author_id에 종속되고 있다.
쉽게 이야기 하자면 중복된다. 그렇다면 앞에서 했듯이 테이블을 나누어 보자.
| title | description | created | author_id |
|---|---|---|---|
| MySQL | MySQL is … | 2011 | 1 |
| ORACLE | ORACLE is … | 2012 | 1 |
| id | name | profile |
|---|---|---|
| 1 | kim | developer |
위와같이 3NF을 만족하는 모델링이 완성되었다. 강의를 보고 무작정 따라 쓰다보니 상당히 난잡하고 보기 어려운 감이 있다.
개인적으로는 이 블로그가 상당히 쉽게 설명하여
이해를 돕기에 편할 것 같아 링크를 남긴다.
물리적 데이터 모델링
이상적인 표를 구체적인 제품에 맞는 표로 변화시키는 작업이다. 이 작업에서는 성능이 가장 중요한 부분이다. 구체적으로 성능 향상을 위해 할 수 있는 방법은 속도가 느린 쿼리를 찾는 방식이다. 이는 각각의 DB마다 사용법이 다르다.
속도 개선 방법
속도 개선을 위한 방법으로는 무엇이 있을까? 우선 가장 쉽게 생각할 수 있는 것은 인덱싱이다.
인덱싱은 write에서 정렬에 필요한 시간이 비약적으로 커지지만 읽기 속도에서 성능개선을 가져올 수 있다.
어플리케이션 단에서 캐싱을 한다면 데이터베이스에 부하를 줄일 수 있는데, 이러한 방법도 속도를 줄일 수 있는 방법일 것이다.
하지만, 만약 이러한 방법에도 불구하고 성능개선이 미미하다면 denormalizaion 즉, 역정규화를 생각해볼 수 있을 것이다.
역정규화는 기존에 있던 테이블을 고치는 작업이기에 최후의 보루로 남겨두는 것이 좋다.
정규화 vs 역정규화
정규화는 쓰기를 위해 읽기를 희생시키는 작업이다. 물론 반드시 그렇다는 것은 아니니 성급한 일반화는 지양하도록 하자.
join이라는 작업은 간단한 자료구조를 알고 있다면 성능 개선이 아무리 좋더라 해도 쉽게 할 수 있는 작업이 아니라는 것을 예상할 수 있다.
그렇기에 쓰기 작업은 편할지 모르지만 읽기 작업에서 부하가 일어날 수 있다.
Refernce
- 생활코딩, 관계형 데이터 모델링, https://opentutorials.org/course/3883
- SQLD 개발자 가이드, http://www.dbguide.net/index.db
- https://yaboong.github.io/database/2018/03/09/database-normalization-1/
- https://ko.wikipedia.org/wiki/데이터베이스_정규화