레디스 기본 데이터 타입
Redis?
길게 소개하자면 한도 끝도 없고, 나 말고도 필력 좋은 블로그들이 더 잘 소개했을 것 같기에 간단하게만 중점만 짚어 소개하자면,
레디스는 In-Memory Database로서 고가용성인 메모리에 저장하고 조회한다. 기존 관계형 데이터베이스 앞에 캐싱 시스템으로 이용하기 적합한 것으로 알려져있다. 오픈소스인만큼 다양한 서비스에서 사용되고 있으며, 앞으로 계속해서 중요한 역할을 할 것같아 책에 예제와 함께 내용을 정리해보려 한다.
이번 포스트에서는 레디스의 자료형에 대해 알아보겠다.
모든 내용은 책 Maxwell Dayvson Da Silva, Redis Essentials의 기반하고 있다.
레디스 데이터 타입
레디스의 특징이라면 바로 다양한 자료구조를 지원한다는 점인데, 또 다른 In-Memory Database인 Memcached와 차이가 두드러진다
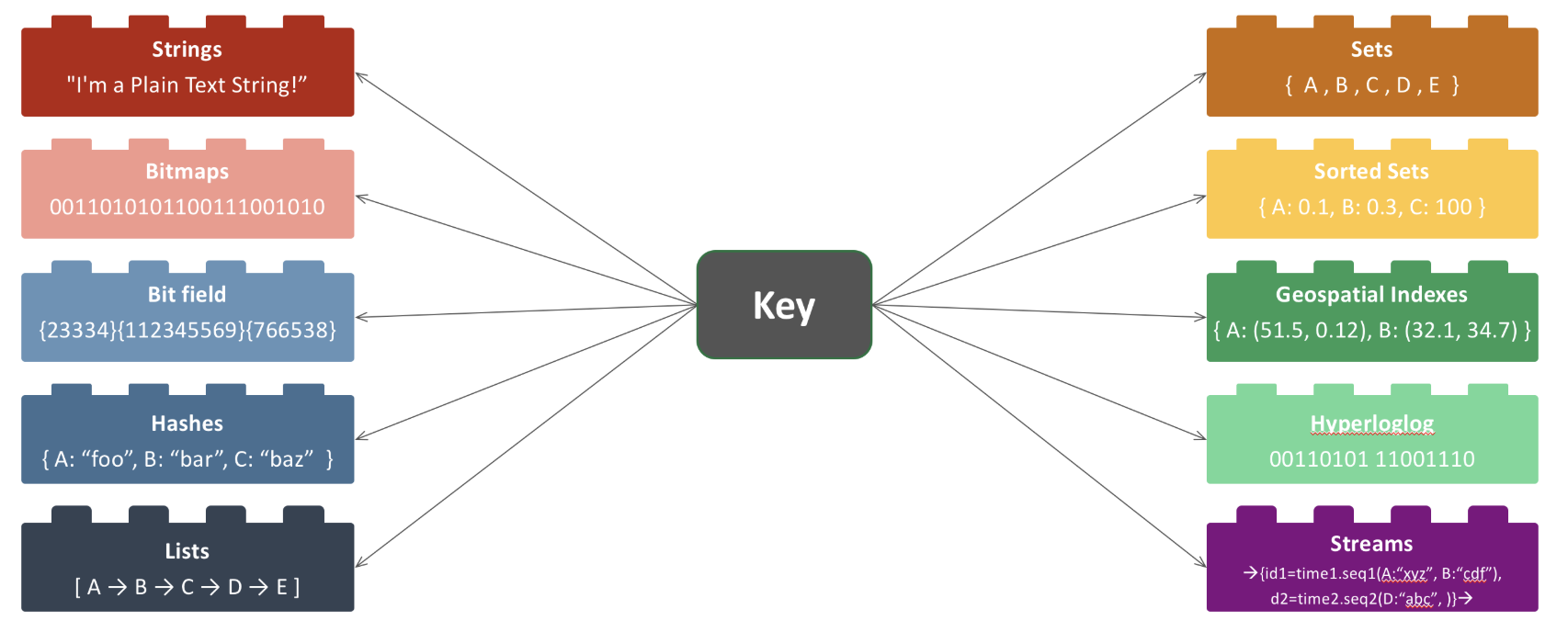
레디스는 기본적으로 String, Bitmap, Hash, List, Set, Sorted Set 를 제공했고, 버전이 올라가면서 현재는 Geospatial Index, Hyperloglog, Stream 등의 자료형도 지원하고 있다.
다양한 데이터 타입을 지원하는만큼 때에 따라 다양한 사용방법을 익히고 적용할 수 있다.
String
스트링 자료구조는 가장 보편적인 데이터 타입이다. 다목적 사용이 가능하며 여러 커맨드를 구비하고 있다. 텍스트 문자열과 정수, 비트맵 등 다양한 타입을 사용할 수 있다. 또한 어떤 형식의 데이터도 될 수 있으며, 512MB를 초과하지 않는 선에서 데이터 타입을 저장 가능하다.
- Cache mechanism: 텍스트나 바이너리 데이터를 캐시 가능하며 API 응답, HTML 페이지의 이미지 혹은 비디오일 수 있다. 간단한 캐싱은
SET,GET,MSET,MGET을 이용하여 가능하다. - Cache with automatic expiration: 자동 만료 키를 사용하여 캐싱을 효과적으로 이용할 수 있다.
SETEX,EXPIRE,EXPIREAT와 같은 커맨드를 사용하며, 데이터베이스 실행 시간이 상당히 길며 캐싱을 같이해야 하는 경우 매우 유용할 수 있다. - Counting:
INCR,INCRBY를 통해 사용가능하다. 카운터는page view,video view,like에 이용될 수 있으며,DECR,DECRBY,INCRFLOATBY등도 제공한다.
MEST MGET
MEST은 다중 키 설정을 도와준다.
MGET은 다중 키 획득을 도와준다.
$ redis-cli
127.0.0.1:6379> MSET first "First Key value" second "Second Key value"
OK
127.0.0.1:6379> MGET first second
1) "First Key value"
2) "Second Key value"
EXPIRE TTL
EXPIRE는 키에 만료 시간을 설정할 수 있다. 만료시간이 자나면 자동으로 삭제되며, 만료시간이 성공적으로 설정되면 1, 아니면 0을 출력한다.
TTL은 아래와 같은 값을 반환한다.
- 양수: 만료까지 남은 시간을 출력한다.
- -2: 키가 존재하지 않거나 만료되었을 경우 출력한다.
- -1: 키가 만료시간이 설정되지 않았을 경우 출력한다.
$ redis-cli
127.0.0.1:6379> SET current_chapter "Chapter 1"
OK
127.0.0.1:6379> EXPIRE current_chapter 10
(integer) 1
127.0.0.1:6379> GET current_chapter
"Chapter 1"
127.0.0.1:6379> TTL current_chapter
(integer) 3
127.0.0.1:6379> TTL current_chapter
(integer) -2
127.0.0.1:6379> GET current_chapter
(nil)
INCR INCRBY INCRBYBLOADT
INCR과 INCRBY는 비슷한 기능을 지원한다.
INCR은 키값을 1 올린 후 값을 리턴한다.
INCRBY는 주어진 정수 값을 토대로 키 값을 올린 후 값을 리턴한다.
DECR과 DECRBY는 위 두 커맨드와 상반되게 키 값을 빼는 기능을 제공한다.
INCRBYFLOAT는 FLOAT 값을 더할 수 있다.
위 세 커맨드 모드 양수 음수 모두 사용할 수 있다.
$ redis-cli
127.0.0.1:6379> SET counter 100
OK
127.0.0.1:6379> INCR counter
(integer) 101
127.0.0.1:6379> INCRBY counter 5
(integer) 106
127.0.0.1:6379> DECR counter
(integer) 105
127.0.0.1:6379> DECRBY counter 100
(integer) 5
127.0.0.1:6379> GET counter
"5"
127.0.0.1:6379> INCRBYFLOAT counter 2.4
"7.4"
위에 보여진 커맨드는 ATOMIC하다 즉, 하나의 오퍼레이션으로 취급한다는 것인데 이는 두 명의 서로 다른 클라이언트가 같은 시간의 같은 실행 명렁어를 통해 같은 값을 얻을 수 없다는 것이다.
예를들어, counter 키가 1이라면 서로 다른 클라이언트 A와 B가 INCR을 동시에 입력했을 때 A가 2 B가 3을 받게 될것이다.
Redis is single threaded, which means that it always executes one command at a time. Sometimes, commands are mentioned as atomic, which means that a race condition will never happen when multiple clients try to perform operations on the same key at the same time.
Node.js voting system
var redis = require("redis"); // 1
var client = redis.createClient(); // 2
function upVote(id) { // 3
var key = "article:" + id + ":votes"; // 4
client.incr(key); // 5
}
function downVote(id) { // 1
var key = "article:" + id + ":votes"; // 2
client.decr(key); // 3
}
function showResults(id) {
var headlineKey = "article:" + id + ":headline";
var voteKey = "article:" + id + ":votes";
client.mget([headlineKey, voteKey], function(err, replies) { // 1
console.log('The article "' + replies[0] + '" has', replies[1],
'votes'); // 2
});
}
MGET을 이용하여 키 배열과 콜백함수를 전달한다. 만약 키 값이 없다면 null을 리턴할 것이다.
익명함수 파라미터인replies는 두 개의 밸류를 가진다. 각각 주어진 키 배열 순서대로 매핑된 값이다.
Node.js 클라이언트는 반드시 비동기적
Lists
리스트는 레디스에서 매우 유동적인 데이터 타입이다. 스택, 큐와 같은 기능 또한 구현할 수 있으며, 많은 시스템들이 작업 큐를 사용하기 위해 리스트를 이용한다. 이는 동시성을 제공하는 시스템에서 리스트의 동작이 atomic하기 때문이다.
리스트에는 블록킹 커맨드가 존재한다. 만약 클라이언트가 블록킹 커맨드를 빈 리스트에 실행한다면 클라이언트는 새로운 아이템이 들어오기까지 기다린다.(blocking)
레디스 리스트는 Linked List로 구현되어 있기 때문에 맨앞과 맨뒤에 아이템을 insertion, deletion하는 과정이 \(O(1)\)만에 가능하다.
특정 아이템을 액세스 하는데에는 \(O(N)\)이 걸리며, 마찬가지로 맨 앞과 맨 뒤는 상수시간안에 가능하다.
리스트는 list-max-ziplist-entries값보다 작은 원소 개수와 ` list-max-ziplist-value` 값보다 작은 원소 값을 가진다면 최적화와 인코딩이 가능하다. 이는 추후 4챕터에서 알아보도록 하자.
실제 사용 예시
- Event Queue: 이미 많은 툴에서 사용 중이다.
- Storing most recent user posts: 트위터는 최근 유저의 트윗을 리스트에 저장하여 이를 구현했다.
List examples with redis-cli
링크드 리스트인만큼 head와 tail에 데이터 삽입 삭제가 가능하다.
LPUSH:head에 새로운 값을 넣는다.RPUSH:tail에 새로운 값을 삽입한다.
$ redis-cli
127.0.0.1:6379> LPUSH books "Clean Code"
(integer) 1
127.0.0.1:6379> RPUSH books "Code Complete"
(integer) 2
127.0.0.1:6379> LPUSH books "Peopleware"
(integer) 3
LLEN: 리스트의 길이를 반환한다.LINDEX: 주어진 인덱스에 저장된 값을 반환한다. 리스트를 수정하지 않는 커맨드다.
인덱스는 항상 왼쪽에서 오른쪽으로 진행된다. negative-index 또한 가능하다.
$ redis-cli
127.0.0.1:6379> LLEN books
(integer) 3
127.0.0.1:6379> LINDEX books 1
"Clean Code"
LRANGE: 주어진 인덱스 범위 내에 값을 모두 리턴한다. 앞에서 언급했듯이 음수 인덱스가 가능하기에 아래와 같은 예제가 가능하다.
$ redis-cli
127.0.0.1:6379> LRANGE books 0 1
1) "Peopleware"
2) "Clean Code"
127.0.0.1:6379> LRANGE books 0 -1
1) "Peopleware"
2) "Clean Code"
3) "Code Complete"
LPOP: 가장 처음 원소를 리스트에서 제거하면서 동시에 반환한다.RPOP: 가장 마지막 원소를 리스트에서 제거하면서 동시에 반환한다.
위 둘은 RINDEX와 다르게 리스트를 수정하는 커맨드다.
$ redis-cli
127.0.0.1:6379> LPOP books
"Peopleware"
127.0.0.1:6379> RPOP books
"Code Complete"
127.0.0.1:6379> LRANGE books 0 -1
1) "Clean Code"
Hashes
해쉬는 오브젝트를 저장하기에 적절한 저장구조이다. 필드를 값에 대입할 수 있으며, 메모리 사용과 데이터 엑세스에 매우 최적화 돼있다.
해쉬는 String to String 매핑 구조이다.
우리는 위에서 투표 시스템 구현을 통해 일종의 sematic한 해쉬를 구현했다. 하지만, 해쉬를 사용하는 직접적인 이유는 메모리 최적화 때문이다.
hash-max-ziplist-entries 과 hash-max-ziplist-value를 통해 사용가능하며, 챕터 4에서 자세히 알아보겠다.
해쉬는 hash table 혹은 ziplist가 될 수 있다. ziplist는 메모리 최적화된 양방향 링크드 리스트다. 정수는 캐릭터 시퀀스 대신 실제 정수가 저장된다.
ziplist는 최적화에 불구하고 룩업에는 일정한 시간이 걸린다. 반면에 해시 테이블은 상수 시간에 탐색이 가능하지만 메모리 최적화는 되어있지 않다.
Instagram had to back-reference 300 million media IDs to user IDs, and they decided to benchmark a Redis prototype using Strings and Hashes. The String solution used one key per media ID and around 21 GB of memory. The Hash solution used around 5 GB with some configuration tweaks
Using Hashes with redis-cli
HSET: 필드에 주어진 키에 대해 값을 설정한다.HSET key field value와 같은 문법으로 사용할 수 있다.HMSET: 여러 필드 값을 키에 설정할 수 있다. 스페이스로 구분한다.
위 둘은 필드 값이 존재하지 않을 경우 생성하고 있을 경우 덮어쓰기를 진행한다.
HINCRBY: 주어진 인티저 값을 필드에 더한다.HINCRBYFLOAT:INCRBY과INCRBYFLOAT비슷하게 동작한다. 아래 코드에서 확인할 수 있다.
$ redis-cli
127.0.0.1:6379> HSET movie "title" "The Godfather"
(integer) 1
127.0.0.1:6379> HMSET movie "year" 1972 "rating" 9.2 "watchers" 10000000
OK
127.0.0.1:6379> HINCRBY movie "watchers" 3
(integer) 10000003
HGET: 해쉬에서 필드를 반환한다.HMGET: 필드들을 반환한다.
127.0.0.1:6379> HGET movie "title"
"The Godfather"
127.0.0.1:6379> HMGET movie "title" "watchers"
1) "The Godfather"
2) "10000003"
HDEL: 해쉬에서 필드를 삭제한다.
127.0.0.1:6379> HDEL movie "watchers"
(integer) 1
HGETALL: 모든 필드/밸류 페어를 리턴한다.
127.0.0.1:6379> HGETALL movie
1) "title"
2) "The Godfather"
3) "year"
4) "1972"
5) "rating"
6) "9.2"
127.0.0.1:6379>
HSCAN:HGETALL은 해쉬가 많은 필드를 포함할 경우 매우 큰 메모리를 사용하여 레디스 성능의 영향을 미칠 수 있다. 이럴 경우 대책으로HSCAN이 있다.HSCAN은 모든필드를 리턴하지 않고 커서와 주어진 개수만큼 출력하게 한다.
Refernce
- https://medium.com/garimoo/개발자를-위한-레디스-튜토리얼-01-92aaa24ca8cc
- Maxwell Dayvson Da Silva, Redis Essentials